
So a week or so ago I wrote a toy Mandelbrot generator for the BBC Micro, capable of using 2.6-bit fixed point arithmetic to draw a pretty terrible vaguely-Mandelbroid image in twelve seconds. That program is now obsolete: the very poorly named Bogomandel is capable of drawing pretty good actual Mandelbrot and Julia images, at higher precision, faster. Here it is.
Update! I managed to squeeze an extra two bits of precision out of the number representation. There’s a bit of a performance penalty, but it’s possible to zoom all the way in to 0.25 now!
(This is a recording of it running in real time on an emulated BBC Master: a 2MHz 65C02-based machine with 128kB of RAM.)
 Bogomandel running in Jsbeeb
Bogomandel running in Jsbeeb
Run it for yourself in the comfort and privacy of your own web browser, using the Jsbeeb BBC Micro emulator!
Bogomandel's github page
See the code on Github.
Introduction
So the story behind the program is that as I was feeling pretty smug about myself for having rendered fractals at an unprecedentedly fast speed on the BBC Micro, I was chatting to someone about it on the vcfed forums. They, going by the handle reenigne (a.k.a. Andrew Jenner) — one of the minds behind the seminal 8088mph demo — came up with a cunning trick for using tables of squares to speed up Mandelbrot calculations; but that was on the 8088, which has vastly more memory and a generally more 16-bit friendly instruction set than the 6502. So I’d written off the 6502 for high-speed 16-bit fractals.
What happened was that reenigne came up with an idea for using thirteen bit integers, with 4.9 bit fixed point… and then handed me a 65C02 calculation kernel which was pretty much ready to drop into my program.
The use of thirteen bit integers was game changing, and I’m going to explain why, because it’s really interesting.
Mandelbrots
A quick recap: Mandelbrots are graphs of the complex plane, with real numbers along the axis and imaginary numbers along the axis. To determine the colour of any given point , then the simplified version is that I start with and count the number of iterations of until . (With an upper limit, as points inside the set will never reach that point.)
I, however, am but a simple software engineer and don’t understand complex numbers, so I prefer to think of as . Expanding leads (and remembering that ) leads to this:
I can then extract real and imaginary parts, leading to the much more software-friendly:
Drawing pictures of the Mandelbrot set (and the Julia set, I’ll get onto that later) is all about trying to compute this as quickly as is humanly possible.
Fixed point and multiplication
My original program achieved this by having a gigantic lookup table of all
possible numbers multiplied by all possible other numbers. This was
achievable because my numbers were only eight bits wide, and the table was
therefore 64kB, which would fit in the BBC Master’s four paged RAM banks. I
used 2.6 fixed point arithmetic, which essentially means that I scale every
number up by ; is represented by the integer
64.
Where this fell down was that my representation was very limited as to what
numbers it can represent. The smallest number possible was the integer 1,
which represented ; the largest number was
the integer 127 (the top bit is used for the sign), which represented .
Because my entire numberspace only contained 256 different numbers, I could only render images which were 256 pixels wide. Except it was worse; the computation of involves a large intermediate value which may be greater than , even though the end result might not be. So I was simply unable to render pixels where or were large enough where squaring them would cause an overflow. The resulting useful image is only 180x180.
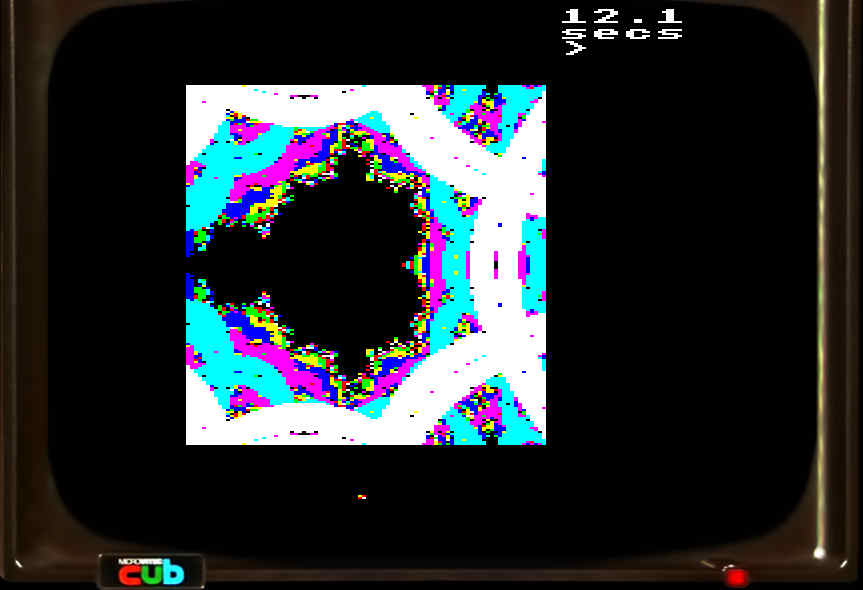
But was still worse: I needed to test for , but my numbers didn’t go as high as … the program actually used a cunning trick which I won’t go into (but which I stole from a blog post on Nothing Untoward, so you can read about it there), which worked for the main lake but was responsible for the strange colours and artifacts surrounding it in the above picture.
Tables of squares
So I needed more precision, to let me represent both bigger and smaller numbers. But moving up from eight bits would have made my multiplication table much bigger; a multiplication table for 16 bit numbers will consume 4GB of RAM, slightly out of reach for a BBC Master
However (and this was reenigne’s insight, not mine), maths can come to my aid.
Consider this:
This can be rearranged to:
My original calculation has a in it, so let me try substituting the expression above in:
This looks like a more complicated expression, but in fact all multiplications which aren’t squares have been eliminated. This is useful, because squares are significantly more tractable for using lookup tables: a table of squares for 8-bit values contains only elements, one for each possible value. The only other arithmetic operations are additions and subtractions, which are cheap, even on a 6502.
However, a table of squares for 16-bit values will contain elements, each of two bytes, so it’s 128kB. That’s still too big to fit in memory. But a table for a 13-bit integer will contain elements, which is 16kB, which will fit nicely in one of the BBC Master’s sideways RAM banks. Suddenly, table lookups for squares are feasible.
Faster speed
The 6502’s really bad at handling 16-bit values — I’ve written some posts on this. To look up one of these squares, I would have to do this (in pseudocode):
to do: result = n^2
offset := n * bytes per entry
address := address of table + offset
result := dereference address
Because the 6502 can only directly manipulate 8-bit values, each of these operations has to be broken down into multiple instructions. Something like this:
to do: result = n^2
lsr n+0
rol n+1
clc
lda #lo(address of table)
adc n+0
sta address+0
lda #hi(address of table)
adc n+1
sta address+1
...etc...
It gets really unwieldy, and quite slow.
This is where reenigne’s second insight comes in: I was working on 13-bit values in a 16-bit word. I didn’t need to put those values in the bottom of the word; I could store them in bits 13 to 1, leaving the bottom bit unused, so I could always set it to 0:
This meant that the integer value of each one my fixed point numbers was even… and as the size of each element in my lookup table is two bytes, this meant that I no longer needed to scale the numbers before adding them to the address of the table. Each number was its own offset into the table!
I could also make use of the top two bits in the word, which are currently
unused: it just so happened that the BBC Master’s sideways RAM bank, where I
wanted to store my 16kB lookup table, is at 0x8000… which is
0b10000000_00000000. If I set the two unused bits at the top to 1 and 0 I
get this:
Now, not only was each number prescaled, but they had the address of the lookup table baked into them. Every valid number was a pointer to its own square!
The long machine code routine above became a very simple (and very fast):
to do: result = n^2
lda (n)
sta result+0
ldy #1
lda (), y
sta result+1
This works because the operations I’m doing, addition, subtraction and taking
the square (via the lookup table), either don’t care about any of these bits
except the bottom 0… and the bottom 0 is harmless because it’s always
0.
I did need to take care to preserve the extra bits when doing computations.
The low bit took care of itself, but the high bit needed some work. Consider
computing 0x8400 - 0x8200 (a.k.a. ). The result is obviously
0x0200 (a.k.a. ). The significant high bit gets lost, so I can’t take
its square without fixing the number up. Luckily, that’s really cheap to do:
to do: result = x - y
sec
lda x+0 ; subtract low byte
sbc y+0
sta result+0
lda x+1
sbc y+1
and #&3F ; perform fixup
ora #&80
sta result+1
It’s only two extra eight-bit instructions — and I only needed to do this on numbers which I wanted to square. There are some intermediate computations which didn’t need fixing up, so I didn’t (or rather reenigne didn’t).
Bailing out
There was final tiny piece of work to do. I needed to iterate until . In components, that’s:
Performing the squares is easy, but square roots are hard. Luckily I didn’t care about the actual value of , only whether it was bigger than . By squaring both sides of the comparison I could test instead; is simply , and hey, I was already calculating this as an intermediate value! So getting proper iteration counts are nigh trivial.
But does it work?
Amazingly well. This (combined with some other optimisations that actually were mine) let it render most images in about thirty seconds; particularly complex scenes are still under a minute.
Of course, 13-bit numbers don’t really have the precision to zoom very far into the Mandelbrot set, and Bogomandel only supports three zoom levels (1, 2 and 4). Julia sets look a bit weird close up, so I think I’m running into precision problems there too, but I’m not quite sure how.
The BBC Master actually has four 16kB RAM banks, all mapped at 0x8000.
Currently Bogomandel uses one. It’s tempting to try to use all of them and
squeeze in another couple of bits of precision, allowing deeper zooms; but
not only would this require switching in the right bank for every table
lookup, but I wouldn’t be able to use reenigne’s baking-in-the-table-address
trick, so I’d have to manually compute the address of the element in the
table. This is all adding up to quite a lot of code, and every cycle in the
kernel matters. So I’m not sure it’s worth it.
Update: I managed to squeeze in another couple of bits of precision. See the writeup below.
But then, that’s what I said last time. If anyone can prove me wrong (update: wronger), I’d be delighted… get in touch!
The result
For completeness, here’s the entire kernel which Bogomandel uses (although I’ve undone some of the self-modifying code for clarity). (The rest of it is here.) (Update: the code here is the 13-bit version, which is now obsolete. See the link for the up-to-date code.)
There are a lot of microptimisations, mainly involving trying to stash intermediate values in registers, but the 6502 only has three registers and can only do arithmetic in one, so there’s not much I can do here.
This routine is not called for every pixel in the image. It turns out that Mandelbrot and Julia sets have the property that any area which is completely bounded by a colour contains only that colour. (Because it’s simply connected.) (No, I don’t understand a word of that paper.) So the program recursively traces out the bounds of boxes, and if all sides of the box are the same colour it fills it and doesn’t recurse in. This leads to a massive performance boost, particularly for the dark lake in the middle of the set, which is very slow to render.
; Once zr, zi, cr, ci have been set up, use reenigne's Mandelbrot kernel to
; calculate the colour.
.mandel
lda #ITERATIONS
sta iterations
.iterator_loop
ldy #1 ; indexing with this accesses the high byte
; Calculate zr^2 + zi^2.
clc
lda (zr) ; A = low(zr^2)
tax
adc (zi) ; A = low(zr^2) + low(zi^2) = low(zr^2 + zi^2)
sta zr2_p_zi2_lo
lda (zr), y ; A = high(zr^2)
adc (zi), y ; A = high(zr^2) + high(zi^2) = high(zr^2 + zi^2)
cmp #4 << (fraction_bits-8)
bcs bailout
sta zr2_p_zi2_hi
; Calculate zr + zi.
clc
lda zr+0 ; A = low(zr)
adc zi+0 ; A = low(zr + zi)
sta zr_p_zi+0
lda zr+1 ; A = high(zr)
adc zi+1 ; A = high(zr + zi) + C
and #&3F
ora #&80 ; fixup
sta zr_p_zi+1
; Calculate zr^2 - zi^2.
txa ; A = low(zr^2)
sec
sbc (zi) ; A = low(zr^2 - zi^2)
tax
lda (zr), y ; A = high(zr^2)
sbc (zi), y ; A = high(zr^2 - zi^2)
sta zr2_m_zi2+1
; Calculate zr = (zr^2 - zi^2) + cr.
clc
txa
adc cr+0 ; A = low(zr^2 - zi^2 + cr)
sta zr+0
lda zr2_m_zi2+1 ; A = high(zr^2 - zi^2)
adc cr+1 ; A = high(zr^2 - zi^2 + cr)
and #&3F
ora #&80 ; fixup
sta zr+1
; Calculate zi' = (zr+zi)^2 - (zr^2 + zi^2).
sec
lda (zr_p_zi) ; A = low((zr + zi)^2)
sbc zr2_p_zi2+0 ; A = low((zr + zi)^2 - (zr^2 + zi^2))
tax
lda (zr_p_zi), y ; A = high((zr + zi)^2)
sbc zr2_p_zi2+1 ; A = high((zr + zi)^2 - (zr^2 + zi^2))
tay
; Calculate zi = zi' + ci.
clc
txa
adc ci+0
sta zi+0
tya
adc ci+1
and #&3F
ora #&80 ; fixup
sta zi+1
dec iterations
bne iterator_loop
.bailout
; iterations contains the pixel colour
Bonus work: Julia sets
For fun, I extended the program to allow it to render Julia sets as well. This uses the same kernel, so it’s very easy.
Mandelbrot and Julia sets both use the same iteration; the difference is that for a Mandelbrot set, I start with ; for a Julia set, I start with and is constant across all pixels. This means that there are infinitely many Julia sets depending on which value of I pick; and, in fact, if I treat the Julia set’s as being a point on the Mandelbrot set, I can see an interesting relationship between how the Mandelbrot looks in the vicinity and the shape of the Julia set.
Bogomandel will allow toggling between the Mandelbrot and Julia sets by pressing the space bar; shift plus the cursor keys will adjust the Julia set’s (and that location will be highlighted on the Mandelbrot set).
Breaking news: better, faster, harder, longer (precision)
After writing the above, I realised that there was a way to use larger
precision without needing to remap the lookup tables. With the right MMU
setup, the BBC Master has contiguous RAM from about 0x0E00 (where my
program is loaded) up to 0xC000. By carefully fiddling the top two bits of
my numbers, I could use 0x4000 to 0xC000 as a 32kB lookup table. This
allowed the use of 14-bit numbers rather than 13-bit. They look like this:
In order to map the number to an address inside the lookup table, I needed to set to if is , and if is . In other words, . This made number fixups more complex, and therefore slower — 10.5 cycles rather than the previous 4 cycles — which made the entire program a little bit slower, but I gained the ability to add another zoom level.
I then managed to add another zoom level by adjusting my number representation; for my 14 bit numbers, I was using 5.9, where five bits were used for the integer part and 9 for the fractional part. This would let me represent numbers from -32 to 32. However, that was complete overkill — the top bit is (almost) entirely unused. So I could rearrange things and use 4.10 instead. Now I was only able to represent numbers from -16 to 16, but that’s fine, and the upside is that I was able to represent numbers all the way down to . This allowed adding another zoom level.
The ‘almost’ in the above sentence is that in rare circumstances I did need numbers outside of the -16 to 16 range; not being able to represent these led to interesting rendering artifacts…
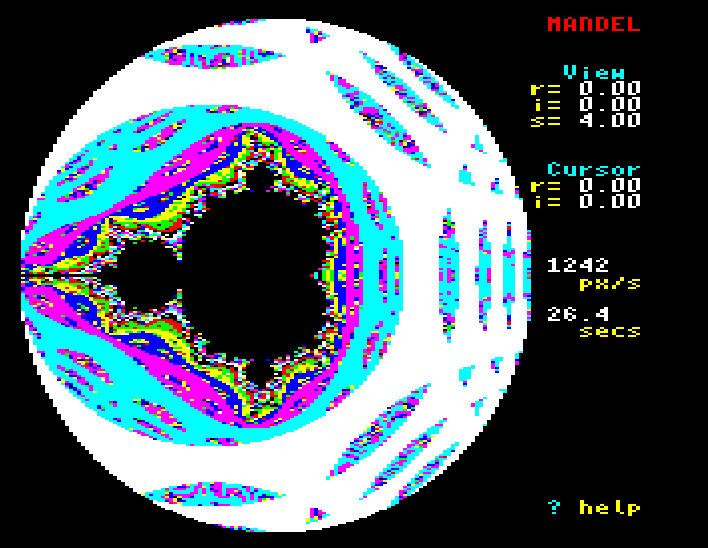
…but I was able to work around this by clamping out-of-range values in the
lookup tables to MAXINT, which prevented the overflow that produced the
artifacts.
So, I gained two levels of precision for very little work. Which was nice.